- Mon 23 October 2017
- Experiments
- akuz
I’ve decided to test a small (not very deep) autoencoder on the audio data. It has two convolutional layers, with convolutions of size 4 and strides of 2, with ReLU nonlinearities. This results in 1/4 frame rate of the original audio.
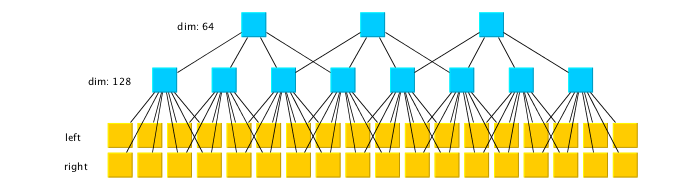
The corresponding deconvolutions are then applied. The network is trained using the Adam algorithm using batches of 100 audio segments of 1024 stereo samples each. This only takes a few seconds, when training on the random batches extracted from the same song, and the parameters converge after 150 iterations. The animation below shows how the ability of the network to encode a random sample of music changes with training, during all 150 iterations (the gif is looped on itself backwards). Notice how it learns the mono features first, and then adjusts them to approximate the stereo music better.
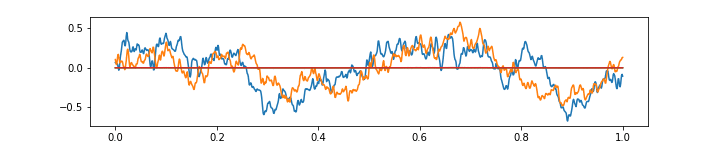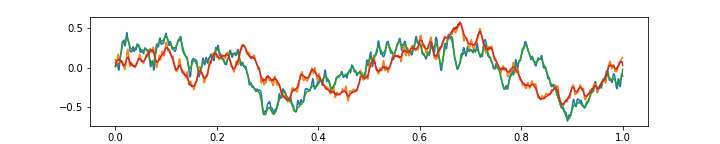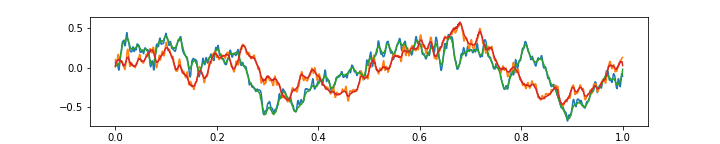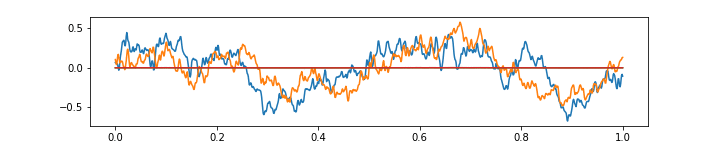
This of course does not result in any compression because, even though we reduced the frame rate to 1/4 of the original, we now have 64 channels per sample versus the original 2 channel stereo. This gave me an interesting idea that with enough structure extracted in the features trained on a single song (or an artist), it might be possible to achieve a very high compression ratio — I am sure somebody is already working on this idea.
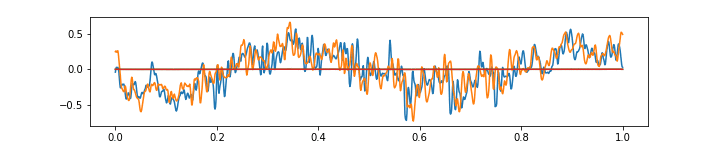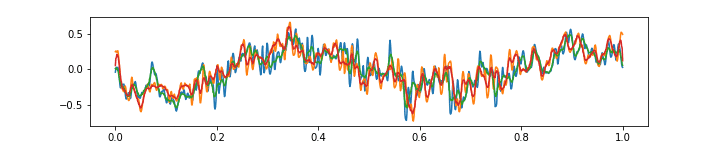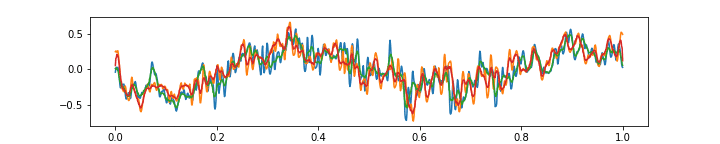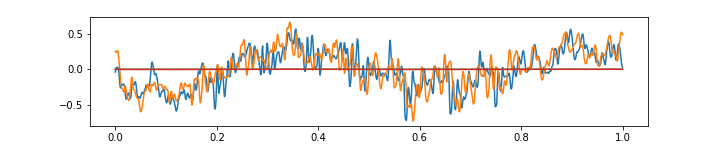
Please see below 3 more gifs (+15 Mb to your traffic) with some further comments on the ability of the above autoencoder to approximate the music with 64 features at 1/4 of the original frame rate.
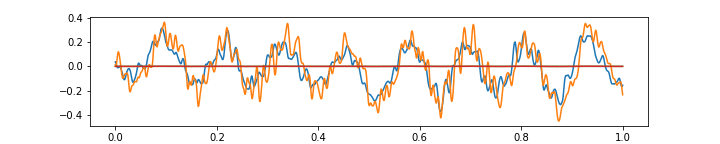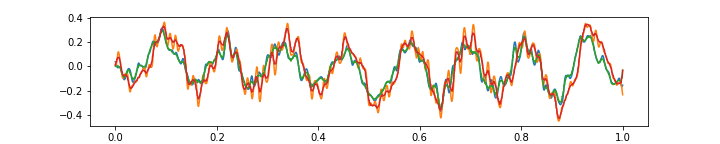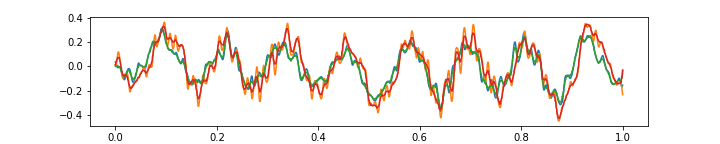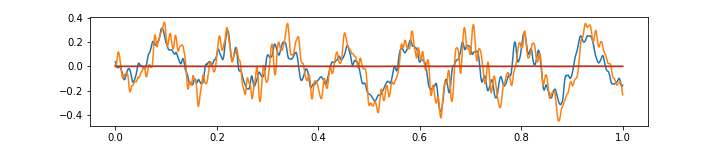
The above gif shows a more or less regular frequency superposition. Notice small imperfections in approximating sharp corners, resulting from having only 64 features in the narrowest autoencoder layer.
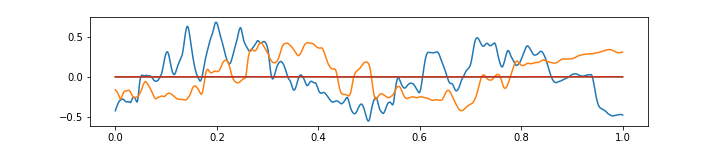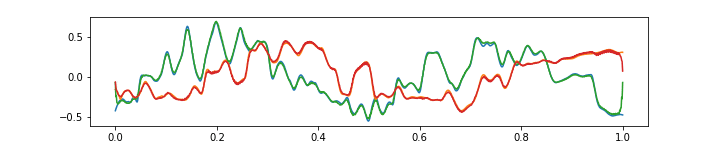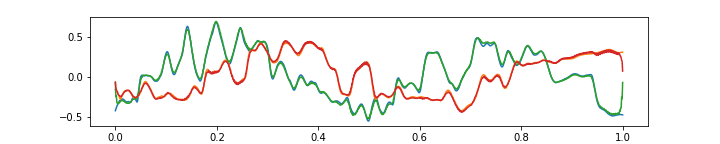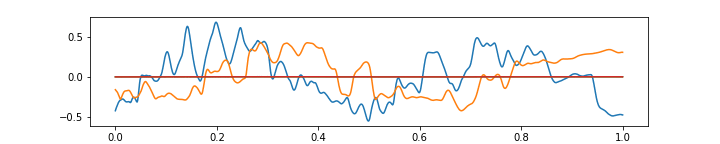
The above gif shows that low frequencies are aproximated rather well. Also, you can see interesting artefacts at the edges of the segment — the network does not have enough “power” to push the approximation away from zero, because the output neurons there receive inputs from the fewer number of inner neurons, because I used ‘SAME’ convolution mode in TensorFlow (this can be fixed with a simple adjustment).
Finally, the above gif shows that the aproximation is not very good with very high frequencies. Of course, this is because there are only 64 features, and moreover each of them has a field of view of 8 audio samples (which is quite wide). It is an interesting question whether the higher frequencies should be approximated at the expense of having more features, or possibly, a special “noise” feature could be added.
You can find a Jupyter Notebook with my code here, but you won’t be able to run it, since it uses some of my audio preprecessing. Anyway, at least you can see my sloppy TensorFlow model, if you wanted to.